Implementing the Transactional Outbox pattern
#microservices-patterns
#distributed-systems
#code
Context
Imagine you and your team are building a microservices-based system, where different services need to communicate to achieve a common goal.
Among the communication options between services - synchronous and asynchronous - you primarily chose asynchronous communication using the Pub/Sub pattern.
In addition, you adopted the Database per Service pattern, where each service is responsible for persisting and maintaining its own data.
In this scenario, when writing to its database, a service also needs to notify interested services about the event that occurred.
How do we guarantee that the change in an entity’s state in the database and the sending of the associated message happen atomically?
The full source code for the implementation we’ll see next is available in the repository: https://github.com/joevtap/blog-demos/tree/main/transactional-outbox
Dual Write Problem
The problem arises precisely when the service needs to perform these two distinct operations atomically (all or nothing):
- Write to the database
- Publish an event to the message broker
If the database operation succeeds, the event publication to the message broker also needs to succeed - otherwise, the system can enter an inconsistent state.

In the diagram above, the database operation happened first and succeeded, but when writing the event to the broker, a network error occurred and the event could not be sent even after retries.

Publishing the event first doesn’t work either. The event can be published successfully and the database write can fail and invalidate the system state.
One possibility is to use distributed transaction solutions, like the X/Open XA and Two-Phase Commit patterns.
The problem is that this kind of solution needs to be supported by both the DBMS and the broker used by the system. Also, Two-Phase Commit is blocking, slow, and complex, making it unviable for this type of system.
Transactional Outbox
Another solution - and the topic of this post - is to take advantage of the transactional properties of a relational DBMS to solve the problem directly in the database.

In step 1 of the diagram, when inserting an order into the orders table the service also inserts the ORDER_PLACED event into the outbox table, both operations within the same transaction.
Thus, when a commit occurs, it is guaranteed that both the state change and the corresponding event were persisted successfully.
Eventually (step 2 in the diagram), another process - which periodically queries the outbox table - publishes the event to the message broker.
This implementation of the Transactional Outbox pattern is called a Polling Publisher, given the nature of the process that publishes messages (called a message processor or message relay).
Implementing Polling Publisher
This approach is quite flexible: it works with any relational DBMS (and even some non-relational ones) and any messaging system.
In our case, I’ll use PostgreSQL as the database and NATS JetStream as the message broker.
The orders service and the message relay will run in the same process: a program written in TypeScript running on Node. The service and the relay can also be placed in separate processes.
First, we need to define a schema for our database:
CREATE TABLE orders (
id SERIAL PRIMARY KEY,
product_id INTEGER NOT NULL,
amount INTEGER NOT NULL,
status TEXT NOT NULL DEFAULT 'pending'::TEXT,
created_at TIMESTAMP WITHOUT TIME ZONE DEFAULT NOW(),
updated_at TIMESTAMP WITHOUT TIME ZONE DEFAULT NOW()
);
CREATE TABLE outbox (
id SERIAL PRIMARY KEY,
aggregate_id TEXT NOT NULL,
aggregate_type TEXT NOT NULL,
payload JSONB NOT NULL,
sequence_number INTEGER DEFAULT 0,
created_at TIMESTAMP WITHOUT TIME ZONE DEFAULT NOW(),
processed_at TIMESTAMP WITHOUT TIME ZONE NULL,
UNIQUE (aggregate_id, sequence_number)
);The aggregate_id and aggregate_type columns refer to our order entity persisted in the orders table. This naming comes from Domain-Driven Design, which also has associations with microservices.
The payload column contains the content of our message, which usually provides the context of the event that should be known by the interested party.
The sequence_number field is important to reorder events on the consumer side if they arrive out of order (which is common and acceptable). The UNIQUE constraint supports this idea.
Finally, processed_at is important so the message relay knows what has already been processed.
We can create a covered index to support the query that the relay will run periodically:
CREATE INDEX idx_outbox_unprocessed
ON outbox (processed_at, created_at)
INCLUDE (id, aggregate_id, aggregate_type, sequence_number, payload)
WHERE processed_at IS NULL;A covered index includes all the fields needed for the query inside the index itself, so it is possible to perform an index only scan, saving some time in the query.
Note that the index is also partial, since we only index records where the processed_at column is NULL, that is, only events not processed by the relay.
In the handler for the POST /orders endpoint of the application, we insert into both the orders and outbox tables using the placeOrder() procedure:
{
//...
handler: async (request, reply) => {
try {
await sql.begin(async (tx) => {
await placeOrder(tx, request.body);
reply.send({ message: "order placed" });
});
} catch {
// ...
}
},
// ...
}interface PlaceOrderProps {
productId: number;
amount: number;
}
export async function placeOrder(tx: TransactionSql, props: PlaceOrderProps) {
const { productId, amount } = props;
const [{ id: aggregateId }] = await tx`INSERT INTO orders (
product_id,
amount
) VALUES (
${productId},
${amount}
) RETURNING id`;
await tx`SELECT 1 FROM outbox WHERE aggregate_id = ${aggregateId} FOR UPDATE`;
const [{ max }] = await tx`
SELECT COALESCE(MAX(sequence_number), 0) AS max
FROM outbox
WHERE aggregate_id = ${aggregateId}
`;
const nextSequenceNumber = Number(max) + 1;
await tx`INSERT INTO outbox (
aggregate_id,
aggregate_type,
payload,
sequence_number
) VALUES (
${aggregateId},
'order',
${sql.json({
type: "ORDER_PLACED",
aggregateId,
aggregateType: "order",
sequenceNumber: nextSequenceNumber,
productId,
amount,
})},
${nextSequenceNumber}
)`;
}We increment sequence_number for each change we make to the aggregate. Inserting an order makes the counter go up from 0 (no events) to 1, with the ORDER_PLACED event.
To perform this increment, we first obtain a lock on the specific aggregate record (using SELECT ... FOR UPDATE), which prevents race conditions.
You might point out that there is repetition in what I’m inserting into the outbox table: some fields are duplicated as JSON in the payload column.
This is intentional for this demo, since I will use the same application and database schema for an alternative implementation to “Polling Publisher” later in this post.
Polling the outbox table
Half of the solution is already implemented.
When changing the state of an entity in the database, we also create the related event in the outbox table, both operations within the same transaction.
Now we need to send the messages from the outbox table to the message broker, which can be done in a separate process to keep responsibilities separated. I chose to do it in the same process as the service.
export async function pollingPublisher() {
while (true) {
try {
await sql.begin(async (tx) => {
const events = await getEvents(tx);
await publishEvents(tx, events);
});
} catch (err) {
console.error(err);
}
await new Promise((resolve) => setTimeout(resolve, POLL_INTERVAL));
}
}Pretty simple code: a loop with a timeout at the end, which is the polling interval.
Even though Node is single-threaded, this function is non-blocking because of the async in its definition.
The getEvents() function runs a query on the outbox table returning the unprocessed messages (leveraging the index we created earlier).
async function getEvents(tx: TransactionSql) {
return await tx`
SELECT id, aggregate_id, aggregate_type, payload, sequence_number
FROM outbox
WHERE processed_at IS NULL
ORDER BY created_at
LIMIT ${BATCH_SIZE}
FOR UPDATE SKIP LOCKED
`;
}We order by the created_at column and limit the query result to an arbitrary amount BATCH_SIZE of records.
Again, this query is executed with SELECT ... FOR UPDATE so the transaction obtains a lock on the affected records, avoiding race conditions.
SKIP LOCKED prevents the transaction from being blocked by other transactions affecting the same records. This is important if our process is scaled horizontally.
Finally, we publish the events we obtained:
async function publishEvents(tx: TransactionSql, events: RowList<Row[]>) {
if (events.length === 0) return;
for (const event of events) {
try {
await publishEvent(event.aggregate_type, {
id: event.id,
aggregate_id: event.aggregate_id,
aggregate_type: event.aggregate_type,
sequence_number: event.sequence_number,
payload: event.payload,
});
await tx`
UPDATE outbox
SET processed_at = NOW()
WHERE id = ${event.id}
`;
} catch (err) {
console.error(`Error when publishing event: ${err}`);
}
}
}When processing an event, we mark it as processed by updating the processed_at column with the current database timestamp.
Note that this operation is NOT atomic. The UPDATE can fail after the event has been published - which, on retry, would cause the same event to be sent a second time.
This is an expected consequence of the Transactional Outbox pattern: events can be sent more than once. That means the delivery semantics of our messages is “at least once”.
Consumers of these messages must ensure that a duplicate message is not reprocessed, that is, they must persist an id for processed messages and discard duplicates that may arrive later.
In other words: consumers must be idempotent.
Polling Publisher and its trade-offs
This implementation has some advantages:
- It is flexible.
- It can be implemented with few lines of code.
- It is independent of third-party solutions.
But it also has disadvantages:
- It introduces latency and eventual consistency (in itself, a set of trade-offs).
- Defining the ideal polling interval and batch size can be challenging.
- The database can become a bottleneck, since it needs to process multiple reads and writes periodically.
Scaling the message relay horizontally
The message relay can be scaled horizontally in a few ways.
One way is to introduce a process responsible for dispatching events from the outbox table to a set of relays, which then process them. This approach works, but introduces yet another bottleneck - in addition to the database itself.
Another alternative is to simply replicate the relay: running multiple instances in parallel, all reading directly from the outbox table.

However, the database remains a bottleneck, since polling requires both frequent reads and writes, and it cannot be scaled horizontally easily.
Additionally, there is no guarantee of global ordering of events.
That lack of global ordering, however, should not be seen as a serious problem, as long as the system is designed with commutative operations whenever possible, and consumers are prepared to handle out-of-order events.
An alternative to Polling Publisher: Transaction Log Tailing/Change Data Capture
Instead of having a process periodically query the outbox table, it is possible to use a Change Data Capture (CDC) tool that queries the RDBMS Transaction Log to obtain table changes almost in real time.
A widely used tool for this purpose is Debezium.
Initially, I thought of not bringing an implementation using this tool because I believed it didn’t integrate with brokers other than Apache Kafka, through Kafka Connect.
However, there is a standalone version of the tool, Debezium Server, which has connectors for almost all well-known messaging solutions and RDBMSs on the market, including NATS JetStream, which we are using.
As with most things, it’s not all roses: the integration with Apache Kafka is far more mature, allowing horizontal scalability and high throughput.
In a large-scale system, using Apache Kafka as a sink for Debezium can be a smart choice, but for our case, Debezium Server with NATS JetStream as a sink is sufficient.
The diagram below shows the Transactional Outbox implementation using Debezium as a CDC tool:

Debezium connects to PostgreSQL as a source using Logical Replication. The DBMS must be configured beforehand to allow this functionality.
In our demo project, this is done directly in the configuration of the db service in the docker-compose.yaml file:
db:
image: postgres:17.5-alpine3.21
# ...
command:
- "postgres"
- "-c"
- "wal_level=logical"Debezium, therefore, does not read directly from PostgreSQL WAL (Write-Ahead Log), but from a logical replication slot that it creates from a publication, also created by default on its first startup.
Since the Transactional Outbox implementation using CDC involves more configuration than code, unlike the polling implementation, it now makes sense to show the definition of our services in the docker-compose.yaml file:
services:
orders:
build:
context: .
dockerfile: orders.Dockerfile
ports: [8080:8080]
environment:
BATCH_SIZE: 10
POLL_INTERVAL: 1000
STRATEGY: logtailing
DATABASE_URL: postgres://postgres:postgres@db:5432/demo
depends_on: [db, broker]
db:
image: postgres:17.5-alpine3.21
restart: unless-stopped
ports: [5432:5432]
volumes:
- ./docker-entrypoint-initdb.d:/docker-entrypoint-initdb.d
- pgdata:/var/lib/postgresql/data]
environment:
POSTGRES_DB: demo
POSTGRES_USER: postgres
POSTGRES_PASSWORD: postgres
command:
- "postgres"
- "-c"
- "wal_level=logical"
broker:
image: nats:2.11.5-alpine3.22
ports: [4222:4222, 8222:8222]
volumes:
- natsdata:/data
command:
- "--js"
- "--sd=/data"
restart: unless-stopped
debezium:
image: quay.io/debezium/server:3.2
ports: [8081:8080]
volumes:
- ./debezium-conf.d/:/debezium/config/
- debeziumdata:/debezium/data
depends_on: [db, broker]
volumes:
pgdata:
natsdata:
debeziumdata:The broker, db, and orders services were already present for our polling implementation. debezium was added for the CDC implementation.
The debezium-conf.d/application.properties file defines the Debezium configuration needed for it to work as a message relay.
quarkus.log.console.json=false
quarkus.log.level=INFO
debezium.sink.type=nats-jetstream
debezium.sink.nats-jetstream.url=nats://broker:4222
debezium.sink.nats-jetstream.create-stream=true
debezium.sink.nats-jetstream.subjects=outbox,outbox.>
debezium.source.connector.class=io.debezium.connector.postgresql.PostgresConnector
debezium.source.offset.storage.file.filename=/debezium/data/offsets.dat
debezium.source.offset.flush.interval.ms=0
debezium.source.database.hostname=db
debezium.source.database.port=5432
debezium.source.database.user=postgres
debezium.source.database.password=postgres
debezium.source.database.dbname=demo
debezium.source.topic.prefix=outbox
debezium.source.plugin.name=pgoutput
debezium.source.table.include.list=public.outbox
debezium.source.snapshot.mode=initial
debezium.transforms=outbox
debezium.transforms.outbox.type=io.debezium.transforms.outbox.EventRouter
debezium.transforms.outbox.table.expand.json.payload=true
debezium.transforms.outbox.table.field.event.key=aggregate_id
debezium.transforms.outbox.route.by.field=aggregate_type
value.converter=org.apache.kafka.connect.json.JsonConverterA lot of configuration, right? This is perhaps one of the drawbacks of using a CDC tool: the initial setup is much more complex than the counterpart that only needs a few lines of code to work.
Some important properties for our setup:
debezium.source.plugin.name=pgoutputdefines the WAL decoding plugin used by PostgreSQL for logical replication.pgoutputis the default; it’s not the most performant but requires less configuration on our part.debezium.source.topic.prefix=outboxanddebezium.sink.nats-jetstream.subjects=outbox,outbox.>must define the same topic/subjectoutbox(or another name).- The second property is used by the NATS JetStream connector to create the
outboxandoutbox.>(wildcard) topics in the Debezium stream.
- The second property is used by the NATS JetStream connector to create the
- Properties that start with
debezium.transformsanddebezium.transforms.outboxdefine a transformation that Debezium will apply when it captures changes in the tables defined indebezium.source.table.include.list.- This
outboxtransformation is responsible for routing changes in ourpublic.outboxtable to the proper NATS JetStream topic (propertydebezium.transforms.outbox.route.by.field=aggregate_type).
- This
You can see details of this configuration in the following documentation links:
- https://debezium.io/documentation/reference/stable/connectors/postgresql.html
- https://debezium.io/documentation/reference/stable/operations/debezium-server.html#_nats_jetstream
- https://debezium.io/documentation/reference/stable/transformations/index.html
- https://debezium.io/documentation/reference/stable/transformations/outbox-event-router.html
After all this configuration, we have Debezium capturing inserts into the outbox table and routing our events to the outbox.> subject in NATS JetStream.
A consumer interested in events for the order aggregate would subscribe to the subject outbox.event.order, for example. The result looks like this:
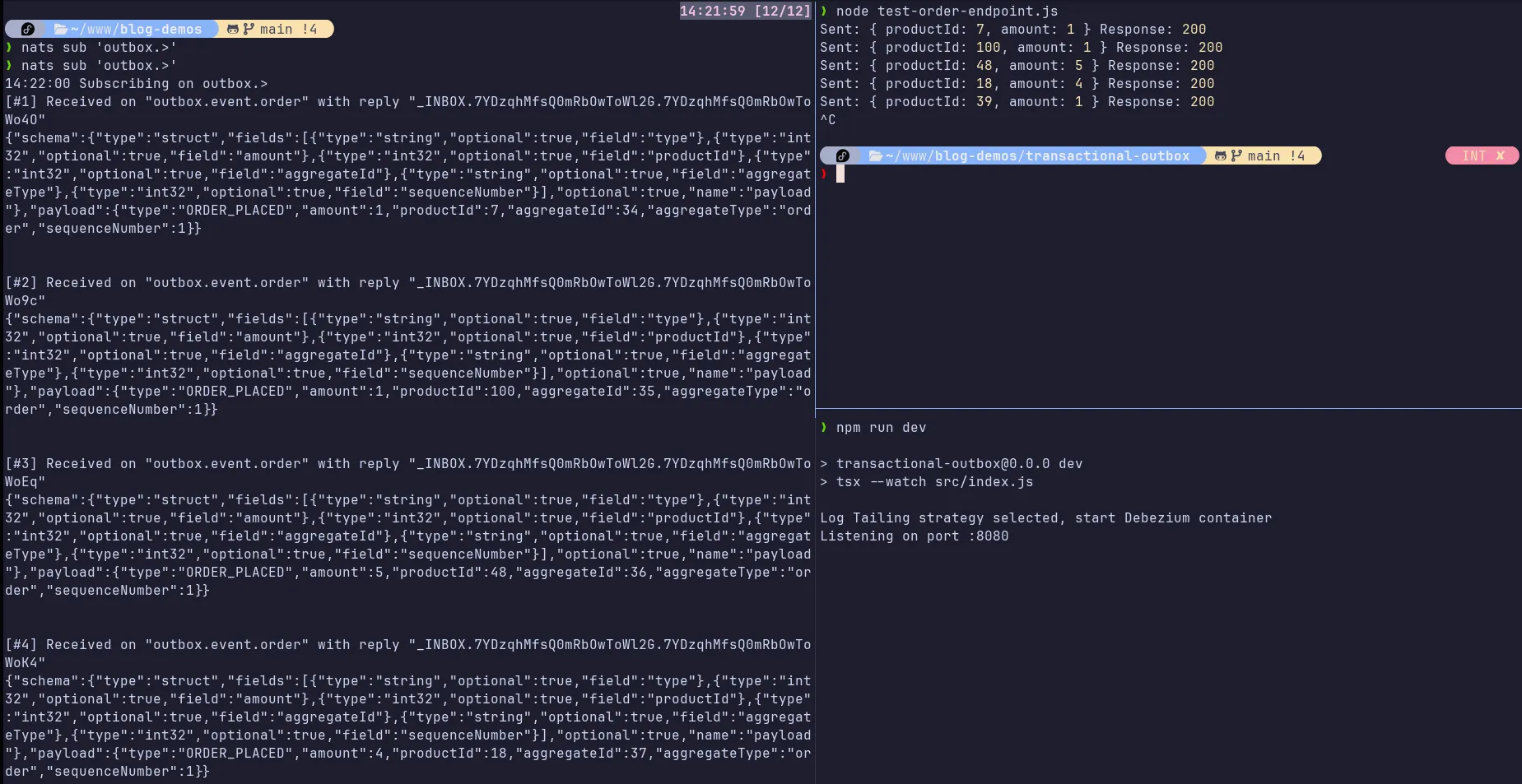
Transaction Log Tailing/Change Data Capture and its trade-offs
This approach has some advantages over the previous one:
- Greater reliability, by using PostgreSQL logical replication.
- Better performance, since it doesn’t overload the database with frequent reads and writes.
- Production readiness, Debezium is widely adopted in the market for this purpose.
- High scalability, especially when integrated with Apache Kafka via Kafka Connect, enabling horizontal scalability and high throughput.
On the other hand, it also brings some disadvantages:
- More complex initial setup, especially when it involves managing an Apache Kafka cluster.
- Requires a separate and relatively heavy process (Debezium).
- Introduces an external dependency, even if it is a well-established tool in the market.
Conclusion
In this post, I presented a classic problem in the context of distributed systems and microservices: the Dual Write Problem, and explored two approaches based on the Transactional Outbox pattern to solve it.
We saw that, when using distributed transactions like Two-Phase Commit or X/Open XA is not viable (either due to complexity or lack of support), the Transactional Outbox becomes a practical and effective alternative.
Although it is not the only solution - event-driven architectures can also use Event Sourcing, for example - the Transactional Outbox pattern is useful in scenarios where events as the source of truth would only result in unnecessary complexity.
The choice between the presented approaches (Polling Publisher vs. Transaction Log Tailing/Change Data Capture) depends on several factors in the context: scale, operational complexity, latency requirements, and so on. That’s why I only focused on highlighting the trade-offs of both approaches so you can make an informed decision.
The implementation shown here is simplified and not production-ready. Important aspects like monitoring and observability are missing, as well as other resilience mechanisms like Dead-Letter Queue.
As a next step, it would be interesting to incorporate performance tests. I’m open to feedback, criticism, and contributions to improve this content.
References
- https://microservices.io/patterns/data/transactional-outbox.html
- https://microservices.io/patterns/data/polling-publisher.html
- https://microservices.io/patterns/data/transaction-log-tailing.html
- https://microservices.io/patterns/data/event-sourcing.html
- https://ederfmatos.medium.com/implementando-transactional-outbox-com-go-dynamodb-mongodb-kafka-e-rabbitmq-7d2c4a7db7d8
- https://medium.com/@xavier_jose/transactional-outbox-pattern-implementation-fa3de00ceba5
- https://eskelsen.medium.com/aplicando-transactional-outbox-pattern-com-debezium-postgresql-e-gcp-pub-sub-para-eliminar-a4b9f858416c
- https://dev.to/fairday/implementing-horizontally-scalable-transactional-outbox-pattern-with-net-8-and-kafka-a-practical-guide-1l1
- https://yektaus.medium.com/using-change-data-capture-and-polling-publisher-in-the-transactional-outbox-pattern-cac5ced14faf